The developers at ASI, which produces the engagement management system iMIS, made an interesting choice for file management. Images uploaded through RiSE, iMIS’s content management system, are stored in a server operating system folder and can be accessed directly with a URL like https://www.example.org/images/sample.jpg. Document files, on the other hand, are stored as content records in the iMIS database, and can only be retrieved using special JavaScript links on a webpage that’s part of the iMIS website. What’s more, such links work only if they exist in the HTML that’s present on the initial page load; if you try inserting links into the HTML using JavaScript, they do nothing.
I still haven’t worked out exactly what sort of black magic happens behind the scenes to retrieve those files from the database when a user clicks on one of the special links, and generally speaking, it’s probably best to use the built-in mechanism for retrieving files. But what if you absolutely need to grab a specific file from the database on demand without using one of the preexisting links?
I’ve determined that it is possible to retrieve and deliver a PDF file stored in the database using the iMIS API. I’ll explain how you can do the same using a custom IQA query, an iPart containing the pdf-lib JavaScript library and the dandavis JavaScript download script, and a bit of JavaScript and jQuery.
About my environment
I should begin by mentioning that I’m developing using a self-hosted instance of iMIS 20.2.65.9955.
I have not tested these methods using an ASI-hosted iMIS installation or with any other version of iMIS.
Creating your IQA query
We’ll begin by using RiSE’s Intelligent Query Architect section to create our custom query. For the purpose of this tutorial, I’m using a folder named KB, and I’m giving my query the name DownloadPDF.
When you create your new IQA query, on the Sources tab, begin by adding Document and Hierarchy business objects listed in $/Common/Business Objects, then add an additional copy of each of those business objects. Join your sources on Document.Document Version Key = Hierarchy.UniformKey, Hierarchy.ParentHierarchyKey = Hierarchy1.HierarchyKey, and Hierarchy1.UniformKey = Document1.Document Version Key.
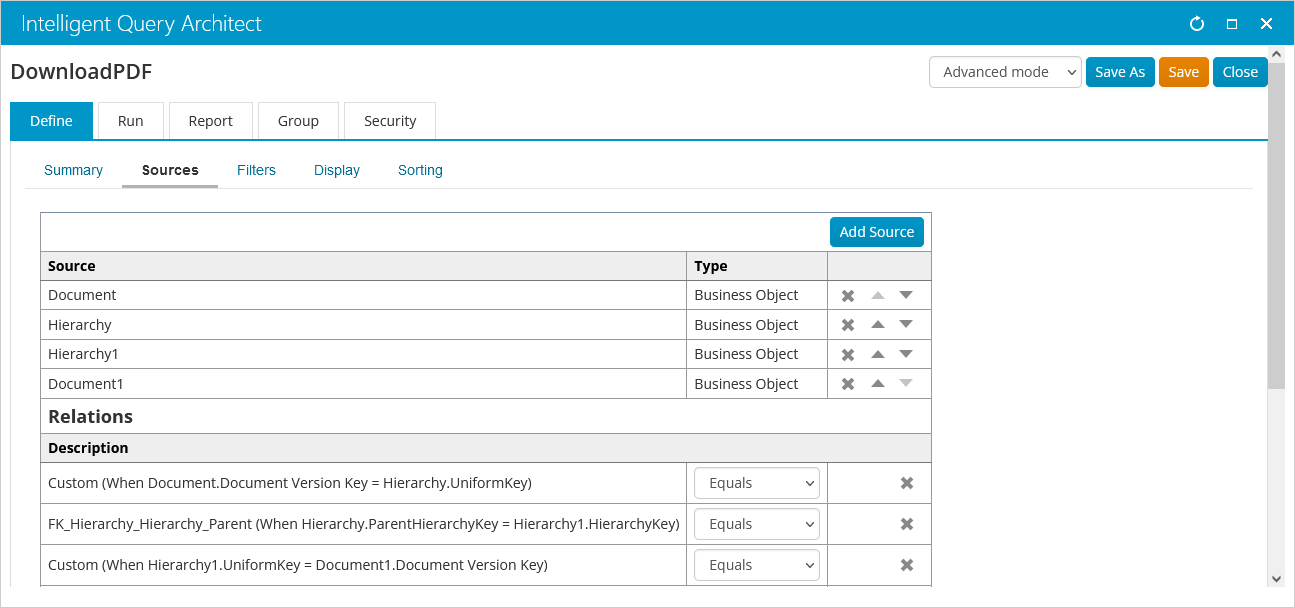
On the Filters tab, specify that Document.Document Status Code must equal 40, Document.Document Name must equal “@url:file”, and Document1.Document Name must equal “@url:older”.
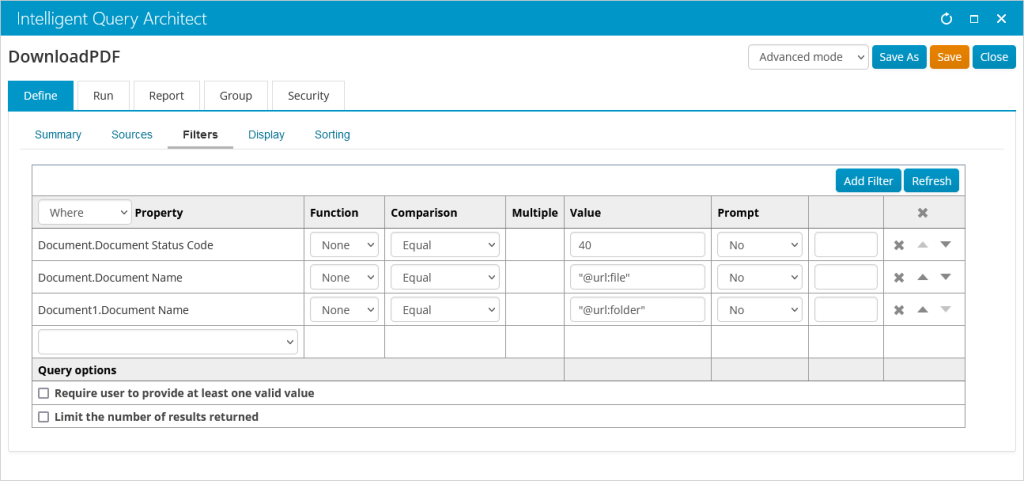
On the Display tab, select Document.Document Name and give it an Alias of File, and select Document1.Document Name and give it an Alias of Folder. Add a custom SQL Expression of CAST(vBoDocument.Blob as VARBINARY(max)) and give it an Alias of FileContents.
Finally, be sure to save your query.
Creating your iPart
I’m using pdf-lib to prepare the contents of PDFs stored in the iMIS database for end users. Even the minified version of pdf-lib weighs in at around half a megabyte in size, which is too large to stuff into a Content Html iPart in a RiSE webpage record, so you can work around that limitation by creating a client-based iPart containing the pdf-lib JavaScript file.
In addition to pdf-lib, I’m using the dandavis download script to handle delivery of PDF files to users’s browsers.
For the purposes of this tutorial, I’m naming my iPart KBpdflib.
Download both scripts and place pdf-lib.min.js and download.min.js in a folder on your computer. In the same folder, save a third file named index.html with the following contents, replacing KBpdflib with whatever name you’re using for your iPart:
<script src="/Areas/KBpdflib/pdf-lib.min.js"></script> <script src="/Areas/KBpdflib/download.js"></script>
Place both JavaScript files and your newly-created index.html in a ZIP file named KBpdflib.
Uploading your iPart
Navigate to RiSE > Document system, then open the ContentItems directory. Go to New > Zip file and select the ZIP file you created.
Next, navigate to RiSE > Maintenance > ContentTypes. If desired, create a subfolder by going to New > Folder, then go to New > Content Type. Give your iPart a name (e.g., KBpdflib) and, if desired, a description; set both URL fields to ~/Areas/KBpdflib/index.html, where KBpdflib equals the name of the ZIP file you uploaded; and then save your Content Type record.
Finally, navigate to RiSE > Maintenance > Deploy Content Items and click the Deploy Content Items button. Assuming everything processes normally, your iPart should now be uploaded.
Identifying a PDF to download
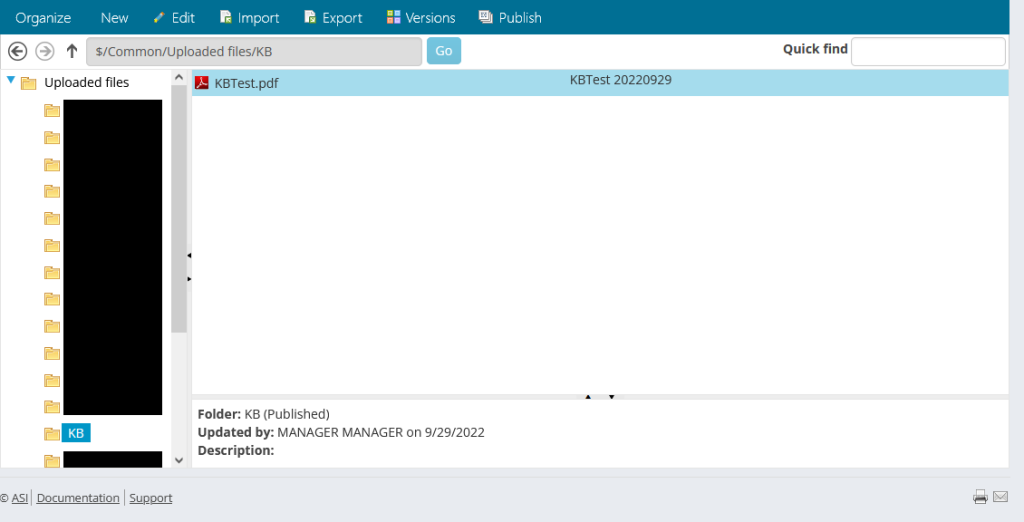
Navigate to RiSE > Page Builder > Manage files. If you have not previously uploaded any PDF files, you’ll need to upload one now; otherwise, make a note of the names of an existing file and the folder in which it exists.
For the purposes of this tutorial, I’m using a file named KBTest.pdf located in the folder named KB.
Creating a webpage to download the PDF file
The heavy lifting is finished at this point; all that’s left to do is create a webpage that makes use of your IQA query and the iPart you created. To do that navigate to RiSE > Page Builder > Manage content; after selecting the folder where you want to store your page, go to New > Website Content.
Give your page a Title and Publish file name, then click Add Content. Select the iPart you uploaded earlier and click OK to insert it into the new page.
Next, click Add Content again and insert a Content Html iPart. Configure that iPart to contain the following HTML code:
<h1>DownloadPDF</h1>
<div id="json-results">
<label for="kb-folder-name">Folder</label>
<input id="kb-folder-name" name="kb-folder-name" type="text">
<label for="kb-file-name">File</label>
<input id="kb-file-name" name="kb-file-name" type="text">
<button id="kb-submit" name="kb-submit" value="Submit">Submit</button>
</div>
After that, click Add Content one more time and insert a second Content Html iPart. Configure that iPart to contain the following JavaScript code:
<script type="text/javascript">
const noResults = "PDF not found.";
const ajaxError = "The PDF failed to load. Please try again.";
document.getElementById("kb-submit").addEventListener("click", function(event) {
event.preventDefault();
downloadFile(document.getElementById("kb-folder-name").value, document.getElementById("kb-file-name").value);
});
// retrieve JSON for specified PDF
function downloadFile(folder, file) {
// maximum number of results to be returned
const maxResults = 10;
// set URL for API call to retrieve PDF
let apiURL = "/api/IQA?QueryName=$/KB/DownloadPDF&folder=" + folder + "&file=" + file + "&Limit=" + maxResults;
// make ajax call to API
jQuery.ajax(apiURL, {
type: "GET",
contentType: "application/json",
headers: {
// we pass __RequestVerificationToken value from webpage so API will return results
RequestVerificationToken: document.getElementById("__RequestVerificationToken").value
},
success: function(data) {
// display results if any were found
if (data["TotalCount"] > 0) {
let fileName = "";
let folderName = "";
let fileContents = "";
// loop through values in JSON string
for (let i = 0; i < data["Items"]["$values"].length; i++) {
// get properties for specific record, then loop through them
let record = data["Items"]["$values"][i]["Properties"]["$values"];
for (let j = 0; j < record.length; j++) {
if (record[j].Name == "File") {
fileName = record[j].Value;
} else if (record[j].Name == "Folder") {
folderName = record[j].Value;
} else if (record[j].Name == "FileContents") {
fileContents = record[j].Value["$value"];
}
}
}
// call script to generate PDF
generatePDF(fileName, fileContents);
} else {
alert(noResults);
}
},
error: function() {
alert(ajaxError);
}
});
}
</script>
<script>
const { degrees, PDFDocument, rgb, StandardFonts } = PDFLib;
async function generatePDF(fileName, fileContents) {
// load file contents retrieved from API
const templatePdfBytes = fileContents;
const templateDoc = await PDFDocument.load(templatePdfBytes);
// serialize PDF document to bytes (a Uint8Array)
const pdfBytes = await templateDoc.save();
// trigger browser to download the PDF document
download(pdfBytes, fileName, "application/pdf");
}
</script>
Click the Save and Publish button to save your new page, then access the page using your browser. Enter you folder and file name in the appropriate input fields and click the Submit button, and the browser should indicate it is downloading the specified PDF.
So, what exactly is going on here? After passing a folder name and file name as part of our API call in the downloadFile function, we’re taking the binary data for the PDF that the API returns and passing it into the generatePDF function, then using PDFDocument.load to provide that data to pdf-lib. pdf-lib then turns it into a downloadable PDF. Pretty neat!
Caveats
This approach does make it possible to deliver PDF files for which links did not exist on a RiSE webpage at the time the page was initially loaded, but there are a few caveats:
- The IQA we created assumes that you have no duplicated folder name/file name combinations. If you have multiple folders with the same name in RiSE, and each of those folders contains files with the same names, the IQA will return data for all matching folder/file combinations. If, on the other hand, you have no folder name duplication, then there’s no problem.
- Retrieving a PDF via the API is slower than using iMIS’s built-in JavaScript links. For relatively small files, the difference may not be significant, but in my testing, multi-megabyte PDFs take significantly longer to download when retrieving the data via the API. With the JavaScript links, the user’s browser will at least display an indication of progress as the file is download; using the API, there’s no indication of any progress until the data has completely downloaded and is ready to go.
- An end user could access any published PDF file that exists in RiSE if he or she knows or can guess the folder and file name and has sufficient permissions to access the folder and file. Before implementing the approach outlined here in a production scenario, you’ll want to ensure any PDF content records that should not be accessible to all users have their permissions set appropriately in RiSE.
In spite of those potential issues, this approach could still be useful. For example, you could create another IQA that retrieves the names of all PDF files stored in a particular RiSE folder, use that query to dynamically generate a list of links on your webpage, and have each link kick off downloading a PDF via the API.